Recently, I was part of a project tasked with setting up temporary email accounts to use when signing up for websites that require email verification. The goal of this project is to limit spam and protect user privacy. While working on this, I began wondering if I could predict the websites that are more likely to sell email addresses by analyzing the text in their privacy policies.
The data I was working with was a list of data breaches that have occurred in the past 10 years. I began exploring the data to examine what types of industries this is common to, and if there are other noticeable trends.
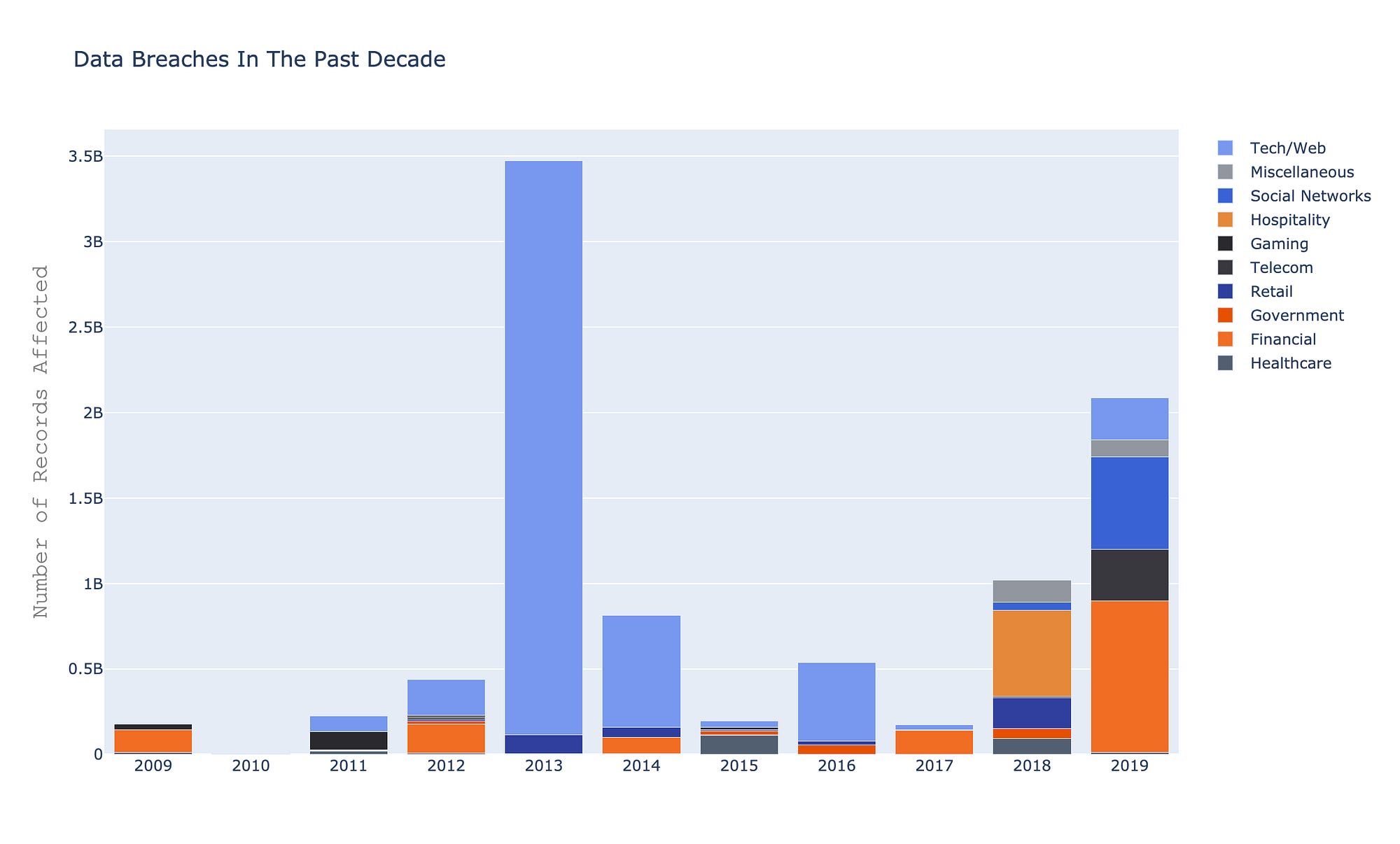
You can quickly notice that this problem spans across many industries and has affected billions of records. There isn’t a foolproof way of solving this — as technology for security improves, so does the technology for those with malicious intent. So wouldn’t it be nice if you could get an idea of how trustworthy a website is based on the language used in its privacy policy?
I decided to take a closer look at the privacy policies of the top 50 websites in the United States. I also used data about these websites that noted how trustworthy they are on a 5 point scale from “Very Poor” to “Excellent.” Long story short, I used NLP to tokenize the privacy policies and created a model to predict the level of trustworthiness based on the text used in each privacy policy. I will walk through these steps below.
The first step was to clean up my target column: website trustworthiness. I decided to go with a black and white scale— excellent or not excellent — and changed the values to 1s and 0s. After completing this step, I had 46 ones, and 3 zeros (plus 1 null.) I knew from the get-go that this limited data would make it difficult to train my model, but I forged on ahead anyways.

Top 20 words before removal of stop words
The next thing I did was prepare the privacy policies to be used in a model. I used the Gensim library to preprocess my privacy policies into tokenized data and remove the common stop words. From here, I converted the raw preprocessed words to a matrix using TfidfVectorizer from Scikit-learn.
Now that I’d gotten my data into the correct format, I used a Nearest Neighbors model with a ball tree algorithm. I fit this model to my matrix of words.
Then, to test out the model, I wrote a sample privacy policy, saying something along the lines of
“We will sell your data to third parties. Nothing is secure. We do not care about your privacy.”
in the hopes that this would predict that the website is not trustworthy.
Sadly, even with multiple attempts and numerous grid searches to find the most optimal parameters, my model was not very successful at predicting the trustworthiness of websites. I attribute this mostly due to my lack of data points for the model to learn from. Another consideration is that the language used in privacy policies does not vary from one to the next.
I have hopes to continue improving my model —by adding more data and privacy policies to compare — which will result in a product that may help users decide how much they can trust the websites that they frequently visit. To view the notebook on GitHub that was created for exploration of this topic, click here.
Click here to view this post on Medium.